
느려터진 구글 스프레드 시트
구글 시트에 수많은 데이터를 넣고 복잡한 함수를 넣다보면 어느 순간 굉장히 버벅거리고 무거운 것을 느끼게 될 겁니다. 데이터를 줄이고, 함수를 날려봐도 어느순간 시트에 접속조차 어려워지는 상황에 처하게 되죠. 저같은 경우는 회사에서 데이터가 수천개 쌓여 있고 복잡한 함수가 걸린 시트에 다수 유저가 데이터 입력하는 상황에서 최적화를 고려해야 하다보니 시트 속도와 최적화에 대해 고민이 많았습니다. 요번 포스트에서는 제가 겪으면서 익혔던 구글 시트를 최적화 할 수 있는 몇가지 팁들을 알려드립니다.
쓰지 않는 셀들은 삭제합니다.
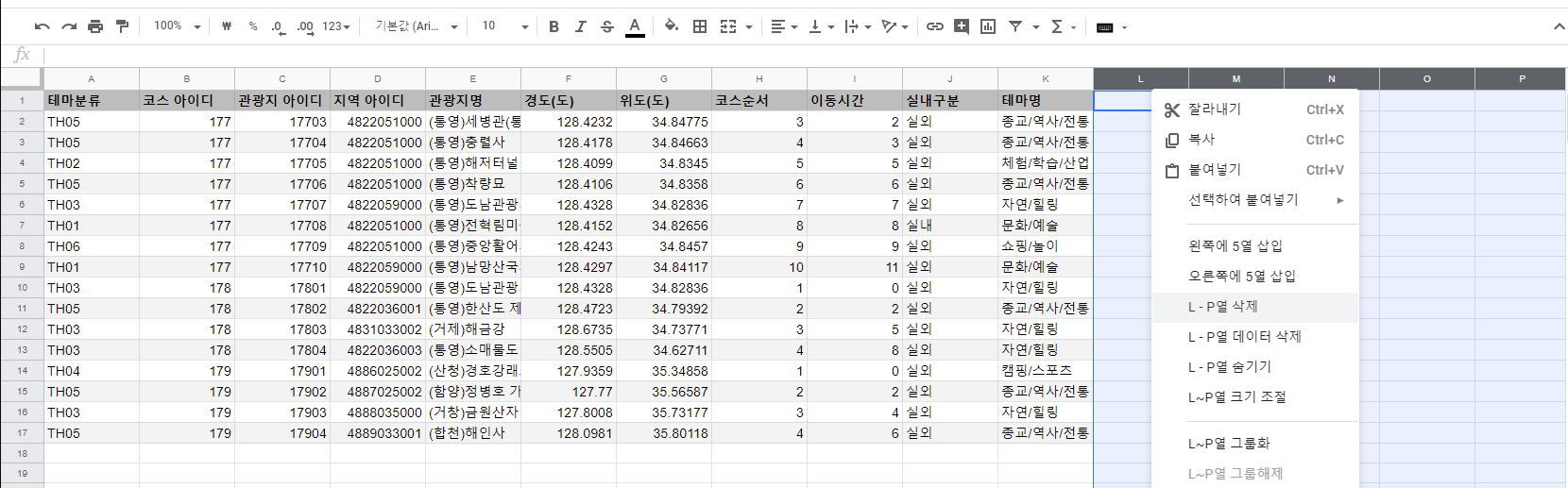
행이 늘어날수록 쓰지 않는 열들의 행도 같이 늘어납니다. 전체적으로 시트 크기가 커지게되죠. 구글 시트는 크키가 클수록 계산이 느려집니다. 빈 셀이 많을 수록 성능에 악영향을 미치게 되죠. 그래서 가능하면 사용하지 않는 셀들은 삭제하는게 좋습니다.
가장 간단한 방법은 쓰지 않는 열들이나 행을 삭제하는 방법입니다. 쓰지 않는 셀들을 삭제하여 데이터 연산속도를 높이고 시각적으로도 깔끔하게 정리된 느낌이 들어 일석이조의 효과를 볼 수 있습니다.
실시간 계산이 필요없는 함수는 값으로 정리합니다.
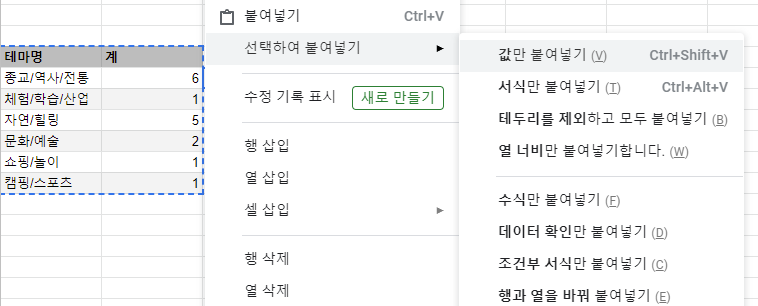
제가 회사에서 일할 땐 실시간으로 볼 수 있는 Dashboard가 필요했습니다. 이 상황에서 실시간 계산을 위해 함수는 필수 요소였죠. 하지만 굳이 함수로 실시간 계산이 필요없는 값들은 함수로 자동 계산되게 하는건 성능면에선 비효율적입니다. 함수로 계산된 값들을 값붙여넣기(Ctrl + Shift + V)로 정리하는 것이 구글 시트의 성능 뿐 아니라 확실하게 마감한다는 점에서 좋은 방법이라고 할 수 있습니다.
함수 참조 범위는 정확하게 지정합니다.
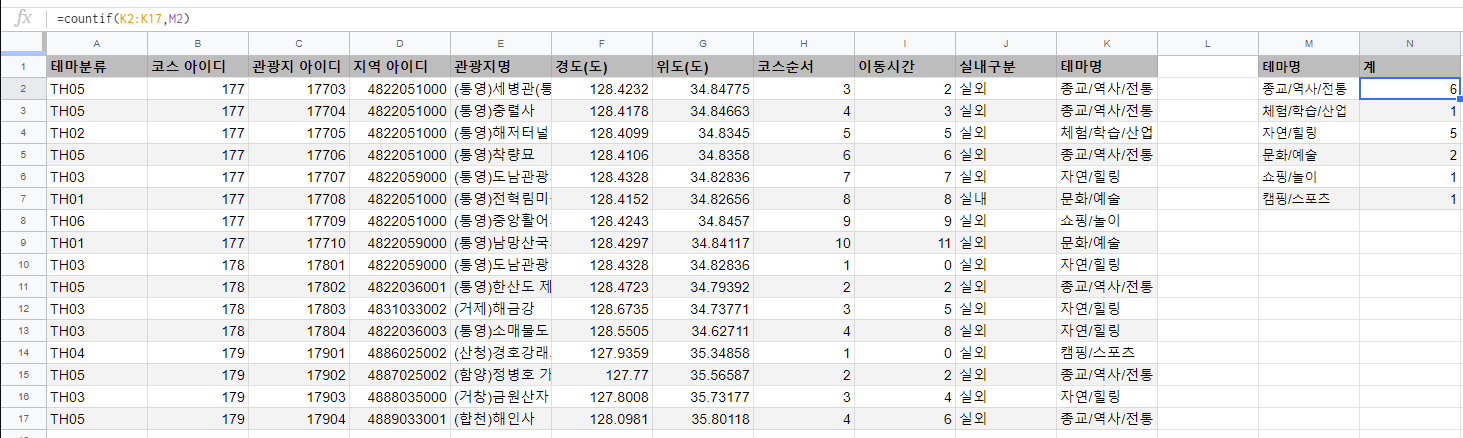
if(), filter(), query() 함수에는 범위가 인자로 들어갑니다. 이 때, 들어가는 범위 인자를 정확하게 입력해주면(K2:K17) 성능면에서 이득을 볼 수 있습니다. 만약 위 사례에서 K:K열 전체를 참조하게 하면 함수가 데이터가 있는 열 외의 범위까지 참조하면서 성능에 악영향을 줍니다.
물론 이건 어디까지나 성능면에서만 봤을 때 유효한 팁입니다. 지속적으로 데이터가 누적되어 테이블 마지막 범위를 알 수 없는 경우, 유지보수면에서는 열 전체를 참조하는게 효율적일 수 있습니다.
자동으로 재계산 되는 함수는 최대한 사용을 줄여주세요
자동으로 재계산되는 함수는 주로 다음과 같습니다.
- NOW() : 오늘 날짜와 시간 계산
- TODAY() : 오늘 날짜 계산
- RAND() : 랜덤한 숫자 계산
이 함수들의 특징은 다른 셀 값이 바뀔 때마다 매번 재계산이 이루어진다는 점입니다. 데이터가 수천~수만행 되는 시트에 이러한 함수들이 행마다 있으면 어떻게 될까요? 매번 수천~수만번씩 재계산이 이루어집니다. 이는 시트가 무거워지고 느려지는데 큰 영향을 끼치죠.
일반적인 실무에선 RAND()함수를 수천~수만행씩 입력해서 유지할 일은 별로 없습니다. RAND()함수를 한번 입력해놓고 각 셀마다 랜덤값이 입력되면 그 값들은 [복사] 후 [값 붙여넣기]로 값만 넣으면 되니까요.
NOW()와 TODAY() 함수는 현재 날짜나 시간을 실시간으로 계산할 때 요긴하게 쓰이는 함수입니다. 하지만 이 함수들을 많은 셀에 입력한 경우 시트가 굉장히 무거워질 수 있다는 단점이 있습니다.
NOW()와 TODAY() 함수 특징은 셀 어디에 넣든 계산되는 값이 똑같습니다. 이러한 특징을 활용해서 한 셀에만 NOW()나 TODAY()함수를 작성하고, 나머지 해당 값이 필요한 셀들에는 이 셀을 참조하여 사용하는걸 권장합니다. 계산은 한 셀에서만 이루어지고 나머지 셀에서는 해당 셀을 참조하는 식으로 함수를 구성하면 보다 더 쾌적하고 가벼운 시트를 구성할 수 있습니다.

MATCH(), INDEX()를 활용한 검색이 최선인가요?
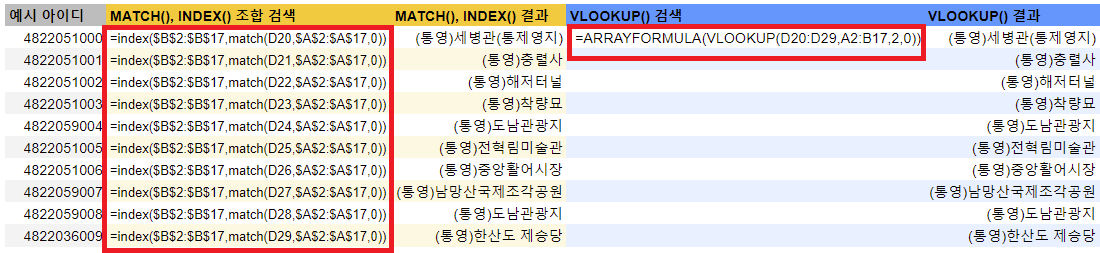
몇몇 엑셀 블로그들 보면 VLOOKUP() 함수보다는 MATCH(), INDEX() 함수를 조합해서 데이터를 검색하는 것이 베스트라고 말하곤 합니다. MATCH(), INDEX() 함수 조합은 물론 강력한 검색 조합식입니다. 테이블이 어떠한 구조로 되어 있던 원하는 값을 찾을 수 있게 해주죠.
하지만 MATCH(), INDEX() 조합은 함수가 두개 또는 세개가 중첩으로 이루어져 있습니다. 계산이 여러번 이루어진다는 것을 의미하죠. 계산이 여러번 이루어질수록 시트는 무겁고 느려질 수 밖에 없습니다.
또한 MATCH(), INDEX() 조합은 VLOOKUP()함수처럼 ARRAYFORMULA() 함수를 통한 배열 계산이 불가능하다는 점도 있습니다. VLOOKUP()과 ARRAYFORMULA()를 조합하면 한 셀에 입력하는 것만으로 열 전체에 검색한 값을 채울 수 있는데, MACTH(), INDEX()조합은 각 셀마다 함수를 넣어서 검색 함수를 넣어야 하죠.
성능 외적으로도 MATCH(), INDEX() 함수는 초보자들에게 익숙하지 않고 직관성이 떨어지다보니 유지보수면에서도 VLOOKUP()함수에 비해 부족한 점이 많습니다.
개인적으로 베스트는 MATCH(), INDEX()를 남용하기보다는 우선적으로 VLOOKUP()으로 검색이 최적화되도록 유니크한 키값을 가장 좌측에 놓고 테이블을 구성하는게 베스트라고 생각합니다. 유니크한 키값은 대표적으로 아이디나 행 번호를 들 수 있습니다. 이런 유니크한 키값들을 설정하며 다른 시트에서도 쉽게 검색할 수 있는 테이블 셋팅이 우선이라고 생각합니다.
이렇게 테이블을 셋팅했음에도 불구하고 VLOOKUP() 함수를 활용할 수 없을 떄, MATCH(), INDEX() 함수를 사용합시다.
'Google Spreadsheet > 사례별 Tips' 카테고리의 다른 글
| [Tip] 특정 패턴 텍스트 추출하기 (0) | 2020.06.24 |
|---|---|
| [Tip] vlookup함수 다중 조건으로 검색하기 (0) | 2020.06.20 |
| [Tip] 알파벳 ABC를 숫자로 변환하기 (0) | 2020.06.20 |
| [Tip] 테이블 랜덤으로 섞기 (0) | 2020.05.22 |
| [Tip] 대소문자 구분해서 카운트하기 (0) | 2020.05.20 |



